Improved distribution matching distillation for fast image synthesis
Methodology
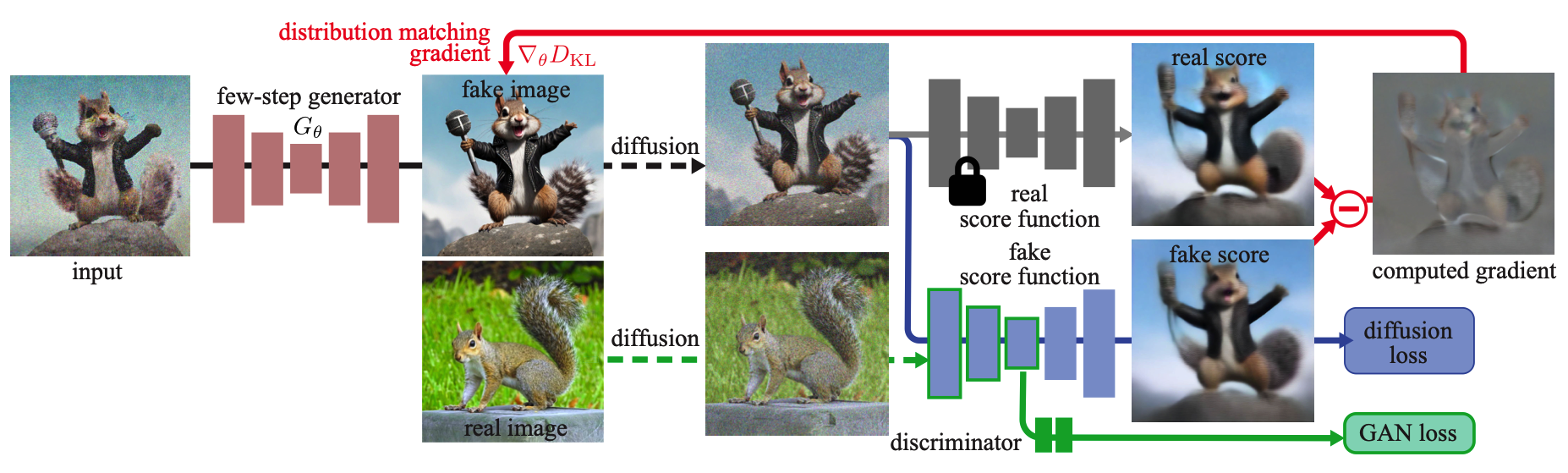
Removing the regression loss: true distribution matching and easier large-scale training
The regression loss used in DMD ensures mode coverage and training stability, but it makes large-scale distillation cumbersome, and is at odds with the distribution matching idea, thus inherently limiting the performance of the distilled generator to that of the teacher model. The first improvement presented in this work is to remove this loss.
Stabilizing pure distribution matching with a Two Time-scale Update Rule
Naively omitting the regression objective from DMD leads to training instabilities and significantly degrades quality. The authors attribute this instability to approximation errors in the fake diffusion model, which does not track the fake score accurately, since it is dynamically optimized on the non-stationary output distribution of the generator.
This is addressed by using different update frequencies for the generator and the fake score model. The authors find that using 5 fake score updates per generator update, without the regression loss, provides good stability and matches the quality of the original DMD.
Surpassing the teacher model using a GAN loss and real data
The model so far achieves comparable training stability and performance to DMD. However, a performance gap remains between the distilled generator and the teacher diffusion model. The authors hypothesize this gap could be attributed to approximation errors in the real score function used in DMD. Since DMD’s distilled model is never trained with real data, it cannot recover from these errors.
This issue is addressed by incorporating an additional GAN objective into the pipeline, where the discriminator is trained to distinguish between real images and images produced by the generator. The integration of a GAN classifier into DMD follows a minimalist design: a classification branch is added on top of the bottleneck of the fake diffusion denoiser. The classification branch and upstream encoder features in the UNet are trained by maximizing the standard GAN objective:
where $D$ is the discriminator, and $F$ is the forward diffusion process (i.e., noise injection) with noise level corresponding to time step $t$.
The generator $G$ minimizes this objective.
Multi-step generator
The authors noticed that it is still hard to model highly diverse and detailed images using a one-step generator. This motivated them to extend DMD to support multi-step sampling.
-
A predetermined schedule with $N$ timesteps ${t_1, t_2, \ldots, t_N}$ is fixed, identical during training and inference.
-
During inference, at each step, denoising and noise injection steps are alternated, like in consistency models, to improve sample quality. Specifically, starting from Gaussian noise $z_0 \sim \mathcal{N}(0, \mathbf{I})$, the process alternates between
- denoising updates \(\hat{x}_{t_i} = G_{\theta}(x_{t_i}, t_i)\)
- and forward diffusion steps \(x_{t_{i+1}} = \alpha_{t_{i+1}} \hat{x}_{t_i} + \sigma_{t_{i+1}} \epsilon, \quad \epsilon \sim \mathcal{N}(0, \mathbf{I})\), until the final image $\hat{x}_{t_N}$ is obtained.
- The 4-step model uses the following schedule: 999, 749, 499, 249, for a teacher model trained with 1000 steps.
Previous multi-step generators are typically trained to denoise noisy real images. However, during inference, except for the first step, which starts from pure noise, the generator’s input comes from a previous generator sampling step $\hat{x}_{t_i}$.
This creates a training-inference mismatch that adversely impacts quality.
The authors address this issue by replacing the noisy real images during training with noisy synthetic images $x_{t_i}$ produced by the current student generator running several steps, similar to the inference pipeline. This is tractable because, unlike the teacher diffusion model, the proposed generator only runs for a few steps. The generator then denoises these simulated images and their outputs are supervised with the proposed loss functions.
Putting everything together
Starting from a pretrained diffusion model, the authors alternate between optimizing the generator to minimize the original distribution matching objective as well as a GAN objective, and optimizing the fake score estimator using both a denoising score matching objective on the fake data, and the GAN classification loss (discriminator task). To ensure the fake score estimate is accurate and stable, despite being optimized on-line, the authors update it with higher frequency than the generator (5 steps vs. 1).